FastAI Course, Part III, Frustrations with creating an image classifier
I create my first image classifier and create a 'web app' out of it. Though I succeeded in the end, this project was particularly frustrating.
Other posts in series
Introduction
After reading through Chapter 2 of the Fast AI course/book, it was time I tried putting the ideas into practice. I decided to create a classifier that distinguishes between squash, tennis and badminton rackets. Then using voila and binder, I created a little web app for it: check it out here!
A comedy of errors
This project was frustrating for me. I somehow managed to make numerous errors at every step which could not be straightforwardly de-bugged. I try to describe them here, but I have undoubtedly forgotten many of them.
The Bing API
The instructions from the notes: “To download images with Bing Image Search, sign up at Microsoft for a free account. You will be given a key, which you can copy and enter in a cell as follows.” Sounds simple. I went to the Microsoft website and logged on. This is what I saw:
Hmm, there’s nothing obvious here regarding Bing or APIs. I spent a whole bunch of time looking through all the menus, but to no avail. The instructions made it sound simple, and yet I couldn’t manage. I searched in the FastAI forums and a relevant post was easy to find. It explained the (non-trivial) steps needed. A big non-triviality is that you should be using a Microsoft Azure account, not a Microsoft account. I think the book should make this clearer. It would have saved me (and presumably many others) a bunch of time.
Padding
I downloaded the datasets, viewed some of the images, and deleted the files which were erroneous. Next up was to create a DataBlock with the appropriate transforms/data augmentation. To ensure the images have the correct aspect ratio, I decided that padding is the best option. I tried it, using pad_mode = 'zeros'. It looked alright, but most of the images have white backgrounds, so I thought maybe it would be better for the images to be padded with white space. I guessed that pad_mode = 'ones' would work, but alas it did not. So, I did what has been recommended numerous times, and went to the docs.
This is what I found:

Maybe I am in the minority, but I do not find this helpful. Here are some things that frustrate me about this:
- What are the possibilities for
*argsand** kwargs? How would I find out? - What does ‘All possible mode as attributes to get tab-completion and typo-proofing’ mean?! What does it have to do with padding images?
- What is
TensorBBox? OrTensorPoint? - What’s the relevance of the change in font in the headings? Is it self-evident? Looking at it more closely, you have one font for classes and one font for methods. But do we need a different font for that? Changing heading formats usually indicates a change in the level of headings, but I don’t think that is what is happening here.
- Most importantly, what are the different options for
pad_mode? If you scroll further down, three examples are provided (zeros, reflection and border), but it is not clear if these are all the options. Maybe they are, maybe they aren’t. I don’t know. - Really, what does ‘All possible mode as attributes to get tab-completion and typo-proofing’ actually mean??
Perhaps I could find out more by looking at the source code. After all, as is emphasised several times in the lectures, most of the source code is only a few lines and thus easy to understand.
class CropPad(RandTransform):
"Center crop or pad an image to `size`"
order = 0
def __init__(self, size, pad_mode=PadMode.Zeros, **kwargs):
size = _process_sz(size)
store_attr()
super().__init__(**kwargs)
def encodes(self, x:(Image.Image,TensorBBox,TensorPoint)):
orig_sz = _get_sz(x)
tl = (orig_sz-self.size)//2
return x.crop_pad(self.size, tl, orig_sz=orig_sz, pad_mode=self.pad_mode)
Yes, there are only several lines of code here. However, they are not helpful, at least not for me. In order to understand any of this, I need to go searching through the rest of the code base, which I am not inclined to do. I should not have to do this to find out if I can create white padding instead of black padding (or maybe I should?).
Anyway, I stopped here with the presumption that it is not possible to get white padding.
RuntimeError: DataLoader worker (pid 19862) is killed by signal: Killed.
I made various other decisions for the DataBlock and created the DataLoaders. Now it was time to do the modelling! I ran the cell, and to my dismay, I got the error message shown in the heading. I didn’t understand it. I checked all my code carefully and did not spot anything wrong. Next I tried to run the examples from the book as is. The same error came up. This was bizarre!
It was time for some Googling. I searched around, saw people with similar error messages, and tried their suggestions. None of them solved the problem. It was time to get to bed at this stage, so I decided I will ask about this in the forum, and have another stab the next day.
Next day, I got ready to tackle the problem and opened up Gradient. But something was a little off:
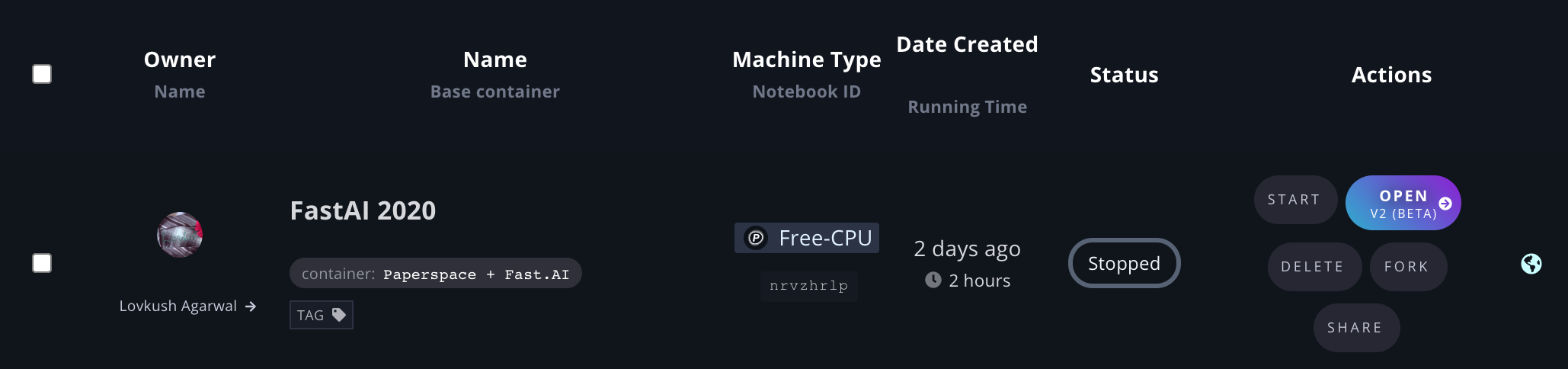
The machine type was set to CPU! I did not remember selecting this, so was a bit confused. Anyway, I tried starting up the notebook, and the pop-up comes up to select the options. The default selection is the CPU. Hmm, that is odd. I tried to change it to GPU, and then I discovered the problem: there was no Free GPU available. It looks like the day before, I just assumed the settings would be the same as previous runs, so I did not check the machine type, and I must have been using the CPU option. This is almost certainly the cause of the DataLoader worker error. At least I now know the issue.
Time to move to Colab.
Google Colab
This is just me, but I dislike the Colab interface. It is similar to Jupyter Notebook, but different in little ways that my brain finds off-putting. One example is that in Colab, the shortcut a to insert a new cell automatically enters the cell; this is not what I want, as I often want to create a bunch of cells at once, and then move into them.
These are minor issues, but I thought I may as well include them, in case anybody else out there gets some comfort knowing they are not alone.
Re-training model post cleaning
I continued with the project, and managed to get the classifier to work. I then cleaned the data using the easy-to-use widget created by FastAI. I then tried to do some further fine tuning, but I got an error message saying that a certain image file, 00000149.png, cannot be found.
I had a little look at the code, and realised my error. I deleted some images while cleaning (including image 00000149.png), but did not re-run the cell that defines the dataloaders dls variable, where the information on the dataset is stored. So I re-ran the cell, and tried again. But I still got the error message.
I wanted to investigate the dls variable to find out what is going on; specifically, I wanted to see which filenames are stored in the variable and check whether 00000149.png is listed there. Similar to the issues I had with the padding above, I did not find the documentation helpful. However, using dir (a super handy function, by the way. It lists all the properties and methods that an object has) and playing a bit, I was able to find the list of filenames stored in dls; 00000149.png was not there!
This left only one possibility: that filenames are stored in the learn variable. Based on my experience with other ML tools (e.g. scikitlearn), this is counter-intuitive to me. At this stage, I just wanted to get a working example as quickly as possible, so I did not investigate how I can do additional fine-tuning cycles on new datasets. Instead, I just created a fresh learner object, and trained that.
I am not sure anybody can do anything about this kind of problem, as it stems from using tools as black-boxes, without understanding how they work. Another example of this I have had is in using conda: I am comfortable creating new environments, but I do not know how to rename a directory or move directories around, because that information is stored somewhere for conda to function, and I do not know how to change that information.
Unfortunately, it does not change that the experience is frustrating - there is a simple task that I want to do, my naive approach does not work, and in order to learn how do it properly, I have to get a fairly comprehensive understanding of the tool. If anybody has any advice or suggestions, do please let me know!
Binder
The next bunch of tasks went well, as far as I can remember. Exporting the learner, creating a local environment where I can create the jupyter notebook that will be turned into the web app, installing all the packages, creating the notebook, getting voila to work locally, and pushing it to github. I was literally one step away: get binder to work. The finish line was literally right in front of me.
Oh boy was I wrong. I do not know how I managed to make such a mess of this step. From what I remember, I encountered two main problems, but my ineptitude dragged out the process far longer than it ought to have.
The first mistake was not to change the File setting to URL, when you enter the path to the file in Binder. This setting was in my blindspot; I never even noticed that box. This is made worse because the voila documentation clearly states that you should do this; in fact, this is how I found the error, because I chose to re-read the instructions carefully, after my various other attempts failed.
The second issue I had was with the requirements file that should be provided. I first tried using the file created by using conda env export, but that did not work. Googling the error messages revealed that conda lists many device specific requirements, which will not work with the Linux machines that binder uses. Googling also showed the two-step process to get around this issue: create a modified version of the requirements by adding some tags to the conda env export command, and then manually remove any requirements that still cause an error on Binder.
This was it: I fixed the two problems and was minutes away from completion. I got binder going, and as it does, it was taking a few minutes to things set-up. But things were taking very long. Something was not right. I just kept waiting, but eventually, the process quit with some other error message.
I was so close, yet so far. I tried searching around on the forums, to see if anybody else had any issues on binder. I ended up finding a blog post and example github repo, so I tried to imitate that. The main takeaway was that they manually constructed a requirements file with 4 or 5 requirements, rather than using an automatically generated file from conda with many more requirements.
After a few more attempts and ironing out several little mistakes (e.g. they used fastai2 in their requirements, which is now out-of-date), it finally worked.
Final remarks
This has been a stressful but enlightening experience. Just writing this blog made me re-live the emotions: the frustration when things seemed unnecessarily complicated, and the sense of achievement and relief when I finally reached the end.
It may sound like I dislike FastAI and the course, but the opposite is true. Like I said in my first post on the FastAI course, I am impressed with the teaching and all the thought that has gone into it. I would strongly recommend this course to anybody interested in AI or Machine Learning. However, I think this may also be why I experience more frustration with it. I have such a high opinion of the course, that any negative stands out; I am holding the team to particularly high standards.
To end, I hope this blog entry has been useful for you in some way. I welcome any comments or thoughts or disagreements; please feel free to let me know.