EuroPython Conference 2020, Day 1
I am attending my first ever tech-related conference. Here I record my thoughts on Day I.
Other posts in series
Introduction
I am attending the online conference EuroPython 2020, and I thought it would be good to record what my thoughts and the things I learn the talks.
08:00, Waking up
I struggled to wake up in time, for two main reasons:
- For the past several months, I have had no need to wake up early, and so my standard wake up time has been 9am.
- I stayed up until 2am watching Round 2 of the Legends of Chess tournament…
But I managed! I then got onto the Discord server to get to the first keynote talk, 30 Golden Rules of Deep Learning Performance, which sounds like it would be particularly insightful. But, unfortunately, the speaker could not give the talk so it was cancelled. At least it gives me time to get breakfast!
09:00, Docker and Python, Tania Allard
Notes of the talk
- Why use Docker? Without Docker, hard to share your models because hard to make sure everyone is using the same modules/appropriate versions of packages.
- What is Docker? Helps you solve this issue with ‘containers’. Bundles together the application and all packages/requirements.
- Difference to virtual machines: Each application has its own container in Docker, which is small and efficient, whereas virutal machine is highly bloated as each applications is grouped with whole OS and unnecessary extra baggage.
- Image - an archive with all the data need to run the app. Running an image creates a container.
- Common challanges in DS:
- Complex setups/dependencies, reliance on data, highly iterative/fast workflow, docker can be hard to learn.
- Describes differences to web apps
- Building docker images. Tania had many struggles/frustrations to learn Docker.
- Many bad examples online/in tutorials.
- If building from scratch, use official Python images, and the slim versions.
- If not building from scratch (highly recommended), use Jupyter Docker stacks.
- Best practices:
- Be explicit about packages. Avoid ‘latest’ or ‘python 3’.
- Add security context. LABEL securitytxt=’…’. E.g. snake.
- Split complex run statements
- Prefer Copy to Add
- Leverage cache
- Clean, e.g. conda clean
- Only use necessary packages
- Use Docker ignore (similar to .gitignore)
- Minimise privilege.
- Run as non-root user. Dockers runs as root by default
- Minimise capabilities user
- Avoid leak sensitive information
- Information in middle ‘layers’ may appear hidden, but there are tools to find them.
- Use multi-stage builds
- This can be overwhelming, and that is normal. Try to automate and avoid re-inventing the wheel.
- Use standard project template, e.g., cookie cutter data science.
- Use tools like repo2docker.
conda instal jupyter repo2docker,jupyter-repo2docker "."
- Re-run docker image regularly. One benefit is making sure you have latest security patches. Don’t do this manually, use GitHub Actions or Travis, for example.
- Top top tips:
- Rebuild images frequently. Get security updates.
- Do not work as root/minimise privileges
- Don’t use Alpine Linux. You are paying price for small size. Use buster, stretch, or Jupyter stack.
- Be explicit about what packages you are require, version EVERYTHING.
- Leverage build cache. Separate tasks, so you do not need to rebuild whole image for small change.
- Use one dockerfile per project
- Use multi-stage builds. f * Make images identifiable
- Use repo2docker
- Automate. Do not build/push manually
- Use a linter. E.g. VSCode has docker extension
My thoughts
A lot of this went over my head. The main lesson I learnt is that I should expect things to be tricky when I eventually do start using Docker. I will refer back to this video when I do start using Docker.
10:00 spaCy, Alexander Hendorf
Notes of the talk
- NLP: avalanche of unstructured data
- Estimate 20:80 split between structured and unstructured ata
- Examples of NLP: chatbots, translation, sentiment analysis, speech-to-texxt or vice versa, spelling/grammar, text completion (GPT-3! :D)
- Example of Alexander’s work: certain group had large number of documents and search engine was not helping them. Used NLP to create clusters of documnets, create keywords, create summaries.
- spaCy. Open source library for NLP, comes with pretrained language models, fast and efficient, designed for production usage, lots of out-of-the-box support.
- Building blocks of spaCy
- Tokenization
- Part of speech tagging. E.g. which words are nouns or verbs, etc.
- Lemmatization. cats->cat
- Sentence boundary detection
- Named Entity Recognition. (Apple -> company). Depends on context!
- Serialization. saving
- Dependency parsing. How different tokens depend on each other
- Entity linking
- Training. Updating models
- Text classification
- Rule-based matching
- Built-in rules
- Rules for specific languages, e.g., adding ‘s’ to end of noun makes it plural in English.
- Usually does not cover many exceptions
- Most languages won’t be supported. Most research done on English.
- Built-in models
- Language models. E.g. word vectors
- Can train your own models with nlp.update()
- Need a lot of data to train these models. Few documents is not enough
- spaCy is pythonic
- should understand objects, iterations, comprehensions, classes, methods
- Might be overwhelming, but not as overwhelming as Pandas yet!
- Pipelines
- Has nice image in slides
- default pipline: tokenize, tag, parse, then your own stuff
- Visualisation
- used to be separate package displacy
- visualisation of sentence grammar/dependencies
- visualise entities. e.g. given sentence, highlight grouping of nounes. e.g. is a word a person, or a date, or an animal, or…
- Serialization
- uses pickle
- Danger zones
- Privacy, bias, law, language is not fixed in stone
- Can’t do all languages
- Extensions
- spaCy universe
- E.g. NeuralCoref. Matching up ‘Angela Merkel’ and ‘chancellor’ recognised as same person.
- Bugs
- spaCy will maintained, and quick response to bug reports
- Extensions more variable
- Status
- Other options: NLTK, Gensin, TextBlob, Pattern
- spaCy: usually close to the state of the art, especially for language models, flexible, extendable via spacy universe, fast (powered by cython)
- For special cases, probably use other models. E.g. RASA for contextual textbots
My thoughts
I have not yet done any NLP, but when I do, I will be sure to look into spaCy after this talk!
10:30 Differential Privacy, Naoise Holohan
Notes of the talk
- Many examples where ‘anonymised’ but actually could still identify individuals by matching data with other data publically available.
- Netflix data. Matched with imdb databse
- AOL data. NYT managed to identify individual and make available their full search
- Limosine service. Person matched it with images of celebrities, and managed to find out about individuals use of taxis/limos
- Many other examples out there.
- Differential privacy. Main idea: blur noise.
- Implemented in diffprivlib, for scikit learn.
- Modules
- Mechanisms. Algorithms to add noise
- Models. Has scikit learn equivalents as its parent class
- Tools. Analogue for NumPy.
- Accountant. Track privacy budget. Help optimise balance between accuracy and privacy.
- Examples
- Gives warning for privacy leakage with certain bound is not specified. If bound is not specified, then original dataset is used to estimate the parameter!
- Pipelines. With and without privacy.
- Without, got 80.3% accuracy
- With, got 80.7% accuracy! Adding noise can actually reduce over-fitting. !!
- Graph of epsilon vs accuracy. Low epsilon highly variable performance. Higher epsilon tends to 80% baseline
- Some exploratory data analysis
My thoughts
I have actually heard of differential privacy before, via this talk from FacultyAI. To anybody interested in this topic, I recommend watching the FacultyAI talk for more background on differential privacy itself.
Main lesson here is that if I want to analyse sensitive data, diffprivlib is a good open source option.
The big surprise factor was that the accuracy can sometimes be better after adding privacy! Adding noise can reduce over-fitting.
12:15, Parallel and Asynchronous Programming in DS, Chin Hwee Ong
Notes of the talk
- Background. Engineer at ST Engineering. Background in aerospace engineer and modelling. Contributor to pandas. Mentor at BigDataX.
- Typical flow: extract raw data, process data, train model, evaluate and deploy model.
- Bottlenecks in real world
- Lack of data. Poor quality data
- Data processing. 80/20 dilemma. More like 90/10!
- Data processing in python
- For loops,
list = [], for i in range(100), list.append(i*i) - This is slow!
- Comprehensions.
list = [i*i for i in range(100)] - Slightly better. No need to call append on each iteration
- Pandas, optimised for in-memory analytics. But get performance issues when dealing with large datasets, e.g. 1>GB. Particularly in 100GB plus range.
- Why not just use spark? Overhead cost of communication. Need very big data for this to be worthwhile. What to do in ‘small big data’?
- Small Big Data Manifesto by Itamar Turner-Trauring
- For loops,
- Parallel processing
- Analogy: preparing toast.
- Traditional breakfast in Singapore is tea, toast and egg
- Sequential processing: one single-slice toaster
- Parallel processing: four single-slice toaster. Each toaster is independent
- Synchronous vs asynchronous
- Analogy: also want coffee. Assume it takes 5 mins for each coffee, 2 mins for single toaster.
- Synchronous execution: first make coffee, and then make toast.
- Asynchronous: make coffee and toast at the same time
- Practical considerations
- Parellelism sounds great. Get mega time savings
- Is code already optimised? Using loops instead of array operations
- Problem architecture. If many tasks depends on previous tasks being completed, parallelism isn’t great. Data dependency vs task dependency.
- Overhead costs. Limit to parallelisation. Amdahl’s.
- Multi processing vs multi threading
- In python
- concurrent.futures module
- ProcessPoolExecutor vs ThreadPoolExecutor.
- Example
- Obtaining data from API. JSON data. 20x speed up versus list comprehension.
- Rescaling x-ray images. map gives 40 seconds. list comprehension 24 seconds. ProcessPoolExecutor about 7s with 8 cores.
- Takeaways
- Not all processes should be parallelized. Amdahl’s law, system overhead, cost of re-writing code.
- Don’t use for loops!
My thoughts
Something for me to investigate. I have not needed to use this yet. Nice bonus - I learnt about Singaporean breakfasts!
12:45, Automate NLP model deployment, William Arias
Notes of the talk
- Background. Colombian, lives in Prague. Works at GitLab
- Often, data scientists are a one-person band. Have to do learn many different tool.
- Define a symphony. Produce flowchart of data workflow. Make explicit where different people can/should contribute to process.
- Favour for yourself
- Makes easier for everyone to understand process
- Symphony components.
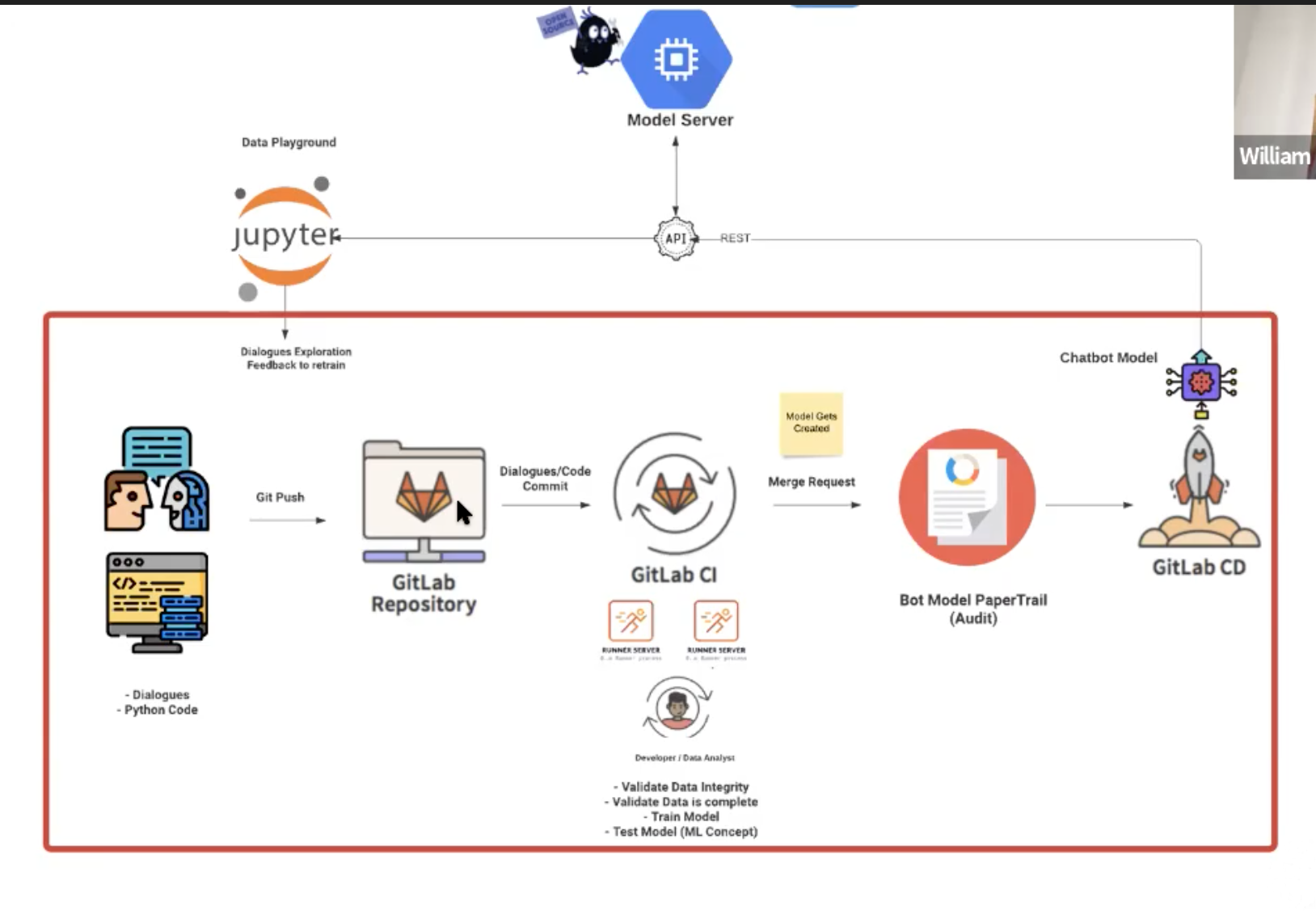
- I found it hard to follow details here. I’d have to re-watch the video.
- This might be standard knowlege for people who already work in software engineering. But somebody with maths background, say, this kind of automation and workflow is not obvious.
- This will make your life easier!
- Has video showing example of making small change to chat bot, and how much is automated.
- See examples on github.
My thoughts
Probably too advanced for me at this stage. But, something I should be aware of when I work on bigger projects.
13:15, Building models with no expertise with AutoML, Laurent Picard
Notes of the talk
- Background, French, ebook pioneer, cofounder of bookeen
- Their definition of ML: given data, extract data.
- Correct definition: AI contains machine learning contains deep learning.
- Graph showing increase of ‘Brain Model’ at Google. Number of directories using it. At 7000 around 2017.
- AutoML - somewhere between ML APIs (developer skills) and ML (machine learning skills).
- Ready-to-use models.
- Vision API. Laurent in 90s tried to detect edges, and it was very hard.
- Label detection. What is in picture?
- Locate picture by matching with google’s database
- Bounding boxes for objects in the picture, e.g. box for trousers, box for person
- Face detection. Emotion prediction.
- Text detection. Identify blocks of text. Works even if image is slanted.
- Hand-writing detection. Not as good as text detection (obviously), but still good.
- Web entity detection/image matching. Identify source of image, identify topic of image. E.g. picture of Tolkien identified as Tolkien and its source found.
from google.cloud import vision
- Video intelligence
- Apply image analysis to each frame
- from google.cloud import videointelligence
- codelabs.developers.google.com/codelabs/cloud-video-intelligence-python3
- NLP
- Syntax analysis. Language detection, syntax analysis (dependency, grammar, etc.)
- Entity detection. Understands context. Given match, gives unique id and wikipedia link!
- Content classification.
- Sentiment analysis. E.g helps company judge how people are talking about their service or product.
- Tutorials available on codelabs
- Translation API.
- Speech-to-text API
- Speech timestamps. Given script and audio, attach
- Text-to-speech. WaveNet by DeepMind
- Cloud AutomL
- You provide data. AutoML does training, deployment and serving
- Can create your own API for cloud model
- For offline, can get TF Lite model for mobile, TF model for browser, or container for anywhere.
- Example of identifying between different types of clouds. Upload around thousand images. Can specify computer hours and visualise results.
My thoughts
Not sure what my takeaway message is here. Looks like a useful and easy to use set of tools. But not sure when I will use it given that I am aiming to become a data scientist.
14:15, Simulating hours of robots’ work in minutes, Eran Friedman
Notes of the talk
- Works at Fabric. Helps develop ground robot.
- SimPy library. Discreate event simulation
- Three objects: environment, …
- And I stopped taking notes.
My thoughts
I do not anticipate needing to know about simulations any time soon, and I am feeling exhausted from first several hours of talks, so I decided to take a break. SimPy looks cool, but not for me.
14:45, Parallel Stream Processing at Massive Scale, Alejandro Saucedo
Notes of the talk
- Chief Scientist at Institue for Ethical AI. Director at Seldon.
- Realtime ML in today’s talk, conceptual intro to stream processing, tradeoffs in different tools, example case
- Real-time ML model for reddit comments. To help automate comment moderation.
- ETL, Extract Transform Load framework for data transformation. Batch processing. Variations: ETL, ELT, EL, LT. Many specialised tools. Image of about 40 different packages that deal with this.
- EL, Nifi and Flume
- ETL, Oozie, Airflow
- ELT, Elasticsearch, Data Warehouse
- Jupyter notebook?
- Batch vs streaming
- Data processed in batches. E.g. periodically
- Stream processing. Process data as it comes in, each data entry at a time. Real time
- In reality, have combination of the two. Rarely all or nothing.
- Stream concepts
- Windows. Can have moving window or tumbling window
- Checkpoints. Keep track of stream progress. Leads to other ideas, e.g. processing at most/at least once.
- Water mark. Somehow allows you to deal with data that arrives later than is expected
- Some tools. Flink, Kafka, Spark, Faust, Apache Beam, Seldon
- Traditional ML workflow. Train a model on cleaning training data. Obtain ‘persisted’ model. Then get unseen data, and use model to make predictions.
- Reddit example: clean text, spaCy tokenizer, TFIDF vectoriser, logistic regression.
You are a DUMMY!!!!->You are dummy->[PRON, IS, DUMB]->[0010, 1000, 1100]->1(which equals moderated).
- Stream-based workflow. Note that ‘core’ is part of Seldon.
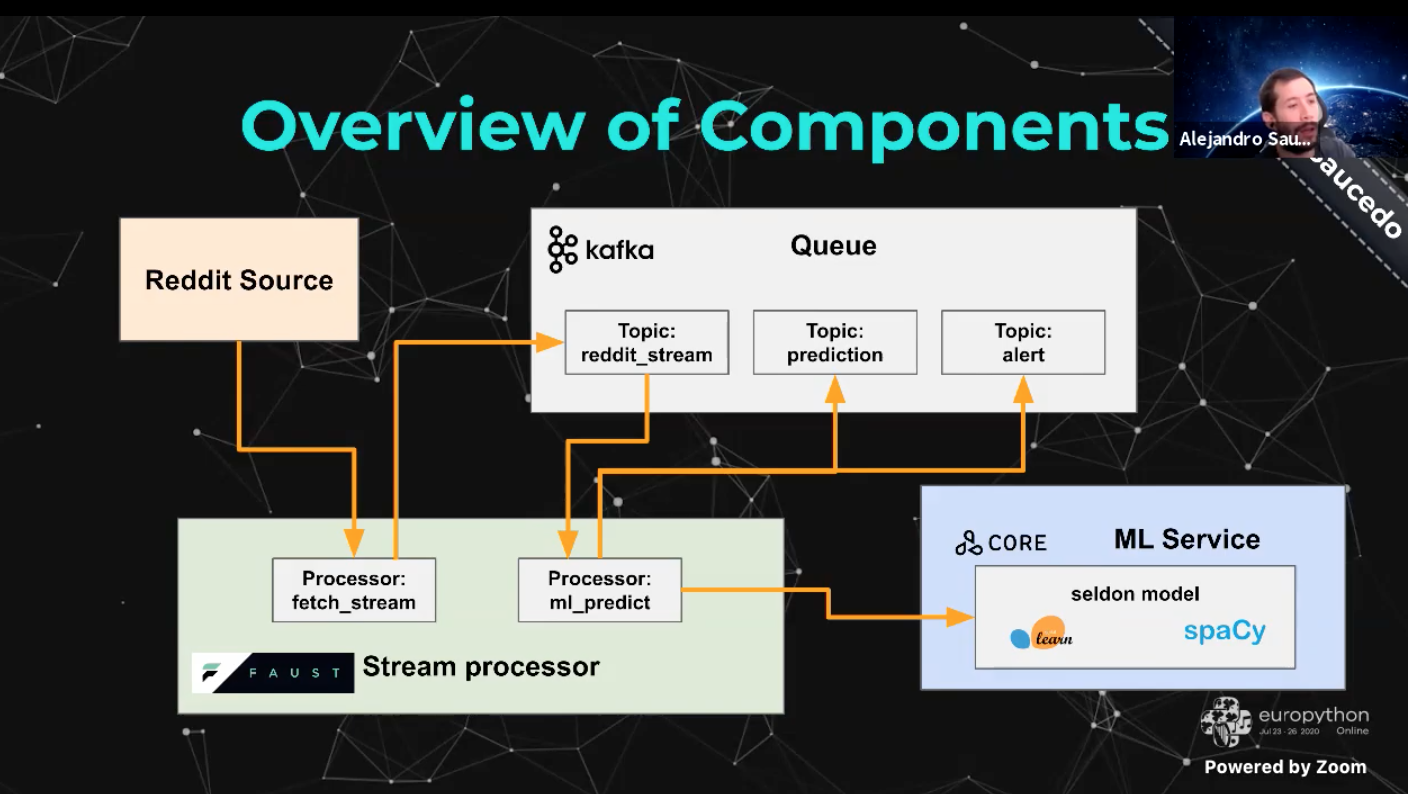
- Gives example code in video for each step in workflow.
- Seldon still developing service. Have open examples on github. They are open to feedback.
My thoughts
Good to learn about this newer workflow and the tools available for stream processing. Again, at this stage of my learning, I am unlikely to use the ideas directly any time soon, but it is good to have an awareness.
18:30, A Brief History of Jupyter Notebooks, William Horton
Notes of the talk
- Tension between traditional python IDE and jupyter notebooks
- “I don’t like notebooks” - Joel Grus
- First Notebook War, Martin Skarynski. Talk at PyData 2018
- Instead of arguing, lets understand the history. Better understanding as as result
- No significant piece of software doesn’t come out of nowhere
- Long-term trends: scientific computing, literate programming, proprietary vs open source, python
- Mathematica, 1988. By Stephen Wolfram. Theodore Gray created Notebook interface. Well received at the time.
- Had two parts to notebooks. Kernel and front-end. Notebooks are objects in themselves that could be manipulated by mathematica.
- The Art of Computer Programming, by Knuth.
- Literate programming. Implemented ‘WEB’ system.
- TANGLE - generates compilable source code
- WEAVE - generate formatted documentation
- Used this idea to implement Tex!
- Maple. In 1992, had ‘worksheet’ interface.
- Maple, Mathematica.
- Mathematical entry vs programming style entry, enter vs shift+enter, etc.
- But both expensive and propritary
- Open source. SciPy, IPython and Matplotlib
- Big name: Fernando Perez. Created IPython in 2001 as grad student.
- …
My thoughts
I stopped taking notes, because I do not think I will need to refer back to this. Time to just enjoy the talk!
19:00, Quickly prototype translation from scratch and serve it in production, Shreya Khurana
Notes of the talk
- Background. Data Scientist at GoDaddy, deep learning NLP
- Workflow in academia is different to business use. Deployment is whole extra part of the workflow.
- Lots of new tools that you wouldn’t be familiar with from just training models.
- Example: seq2seq model i.e. translation. E.g. german sentence to english sentence.
- Small dataset from TedTalk transcripts.
- Fairseq. Used for preprocessing, training, model serving. In some unknown language - shell script?
- Flask. Tool to create API. Development server. Example code given in talk.
- uwsgi. Helps make Flask app secure / ready for production. There is uwsgi.ini file to configure stuff.
- nginx. (pronounced ‘engine-x’). Idea of QPS - queries per second. Make sure all requests are appropriately routed to server. Unknown language for nginx.
- supervisord. coordinates nginx and uwsgi.
- Docker. The above system has many dependencies. Docker creates containers where you can isolate all the requirements and programs, which can loaded up and run remotely.
- General good practice: check logs frequently, caching, unit tests.
My thoughts
A lot of useful information here. I will be returning to this when I have to put a model into production.
19:30, Painless Machine Learning in Production, Chase Stevens
Notes of the talk
- Background. Works for teikametrics
- Focus on production, not on machine learning. Model building is relatively mature, but still need lots of work on improving production.
- Goal of teikametrics - helps online e-commerce businesses.
- Motivation: Ops is intrinsic to ML, ‘MLOps’ is unsustainable (where data scientists pass their models to software engineers). Conclusion: data scientists need to productionise their own models. But data scientists want to do data science. Hence, need tooling and services to make it easier as possible.
- Looked for services to do full cycle (preprocess, train, evaluate, deploy, repeat), but couldn’t find any.
- Interesting graph showing how AUC drops for models over time. Models need to be re-trained! Another example of how covid makes models from 2019 almost useless.
- Different clients will have different markets which require different models.
- Previous two points show importance of having efficient workflow and cycle.
- MLOps is unsustainbly
- Brief history of programming. Punch cards programmers separate from people who run programs, changes with terminal, late 90s, programmers separate from quality assurance and release team, rise of devops.
- MLOps is making similar mistakes of past. Lots of slow back and forth between data scientists and production team.
- Modern experience at tiekametrics.
- Use cookiecutter on their sagemaker-framework. Asked a bunch of questions, which after answering, get repo made with good structure built in.
- Define preprocessing function (SQL, Pandas), define train and validation training sets and model, define model loading function.
- Various details skimmed over. E.g. need to update config file.
- Whole list of tasks that care standardised and made easy. See talk for list.
- Their stack:
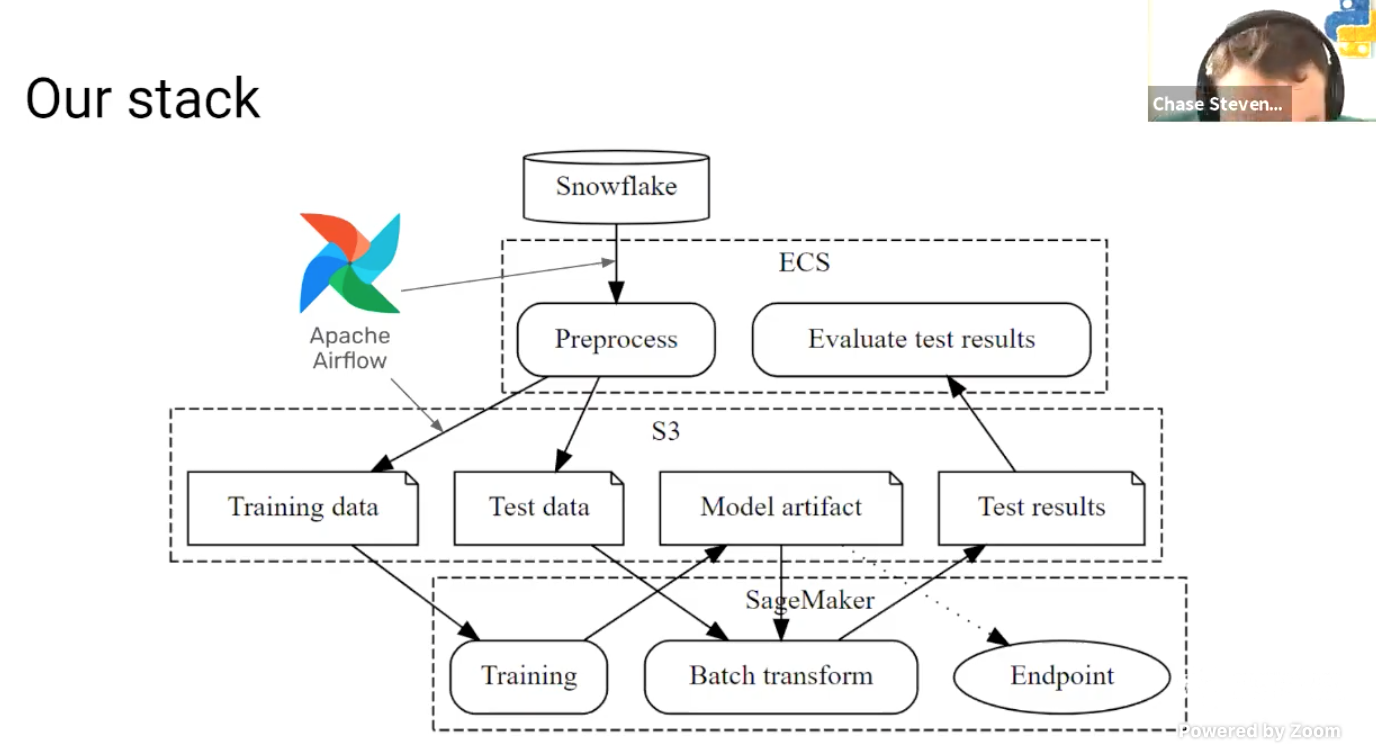
- Various details given in talk
- Big lesson. Do this! Big savings. Even little things: example of automating process of choosing which AWS instance to use.
My thoughts
Another useful set of resources and examples I can use as a reference if/when I need to make production based decisions.