EuroPython Conference 2020, Summary
I tidy up the notes created in the previous two entries of the series, to make it more coherent and to highlight key ideas and lessons.
Other posts in series
Introduction
I attended the online conference EuroPython 2020 and recorded notes while watching the talks. Today, I reviewed the notes with the aim of consolidating the main lessons, grouping together similar talks, and recording key lessons.
Workflows
This seems to be a big theme, and sounds like the next big challenge for the data scientist profession.
GitLab Tools, William Arias
- I found this talk hard to follow, so my notes are not great.
Parallel stream processing, Alejandro Saucedo
- I found this talk hard to follow, but notes are bit better than the example above
- Faust - stream processor
- Kafka - ?
- Seldon - deployment
- Example of developing workflow to use ML to help moderate reddit comments.
Example workflow for Translation, Shreya Khurana
- I found this talk hard to follow, but still managed to take some notes.
- Tools used include: seq2seq, Fairseq, Flask, uwsgi, nginx, supervisord, Docker
Example from teikametrics, Chase Stevens
- Significant time spent emphasising need for good systems and workflows. Make the effort to automate!
- My notes are not great when it comes to actually describing the tools or workflow they used. Watch the video to find out.
- Interesting example at end: they automated task of choosing which AWS instance to use.
DVC, Hongjoo Lee
- Software development has following standard workflow and tools (I don’t know what most of these things mean…):
- Coding management: git
- Build: sbt maven
- Test: jUnit
- Release: Jenkins
- Deploy: Docker, AWS
- Operate: Kubernetes
- Monitor: ELK stack
- Hongjoo goes through live example of using DVC on simple model
- Some alternatives to DVC: git-LFS, MLflow, Apache Airflow
Data pipelines, Robson Junior
- I found the speaker particularly hard to follow. Despite this, it looks like I got some decent notes.
- List of tools for different tasks
- ELT: Apache Spark, dash, luigi, mrjob, ray
- Streaming: faust and kafka, streamparse and Apache Storm
- Analysis: Pandas, Blaze, Open Mining, Orange, Optimus
- Management and scheduling: Apache Airflow
- Testing: pytest, mimesis (to create fake data), fake2db, spark-test-base
- Validation: Cerberus, schema, voluptuous
Example from DeepAR talk, Nicola Kuhaupt
- Workflow was not focus of talk, but talk contained information on workflows anyway
- Integrated into Sagemaker, which has many in built tools
- Ground Truth. Use mechanical turk to build data sets
- Studio. An IDA
- Autopilot. For training models
- Neo. For deployment
- boto3, to access aws
- s3fs, file storage
- Others were also mentioned. Re-watch talk to find them.
NLPeasy, Philipp Thomann
- NLPeasy is intended to make NLP easy
- Has lots of built in tools, e.g. spaCy, Vader, BeautifulSoup
- The talk presented example of analysing EuroPython abtracts
- Had nice dashboard to visualise lots of outputs of models
Kedro, Tam-Sanh Nguyen
- Open source complete workflow package by QuantumBlack
- Talk rushed through features of Kedro, but from the brief glimpse, it looks easy to use and has a nice UI.
- See examples on GitHub or Tam-Sanh’s YouTube series DataEngineerOne
Recommended packages / tools
spaCy, Alexander Hendorf
- Open source library for NLP
- Has many state-of-the-art algorithms built-in
- Highly recommended by the speaker
diffprivlib, Naoise Holohan
- Open source library for differential privacy
- (For background theory on differential privacy, I recommended this talk from FacultyAI.)
- If you want to work with sensitive data, this is a good open source library to consider
Google’s ML APIs and AutoML, Laurent Picard
- Google has a lot of ML tools available
- Looks nicely packaged and looks very user-friendly.
- Is there even any point in me learning data science?!
SimPy, Eran Friedman
- SimPy can be used to do discrete event simulation
- E.g. for robotics training
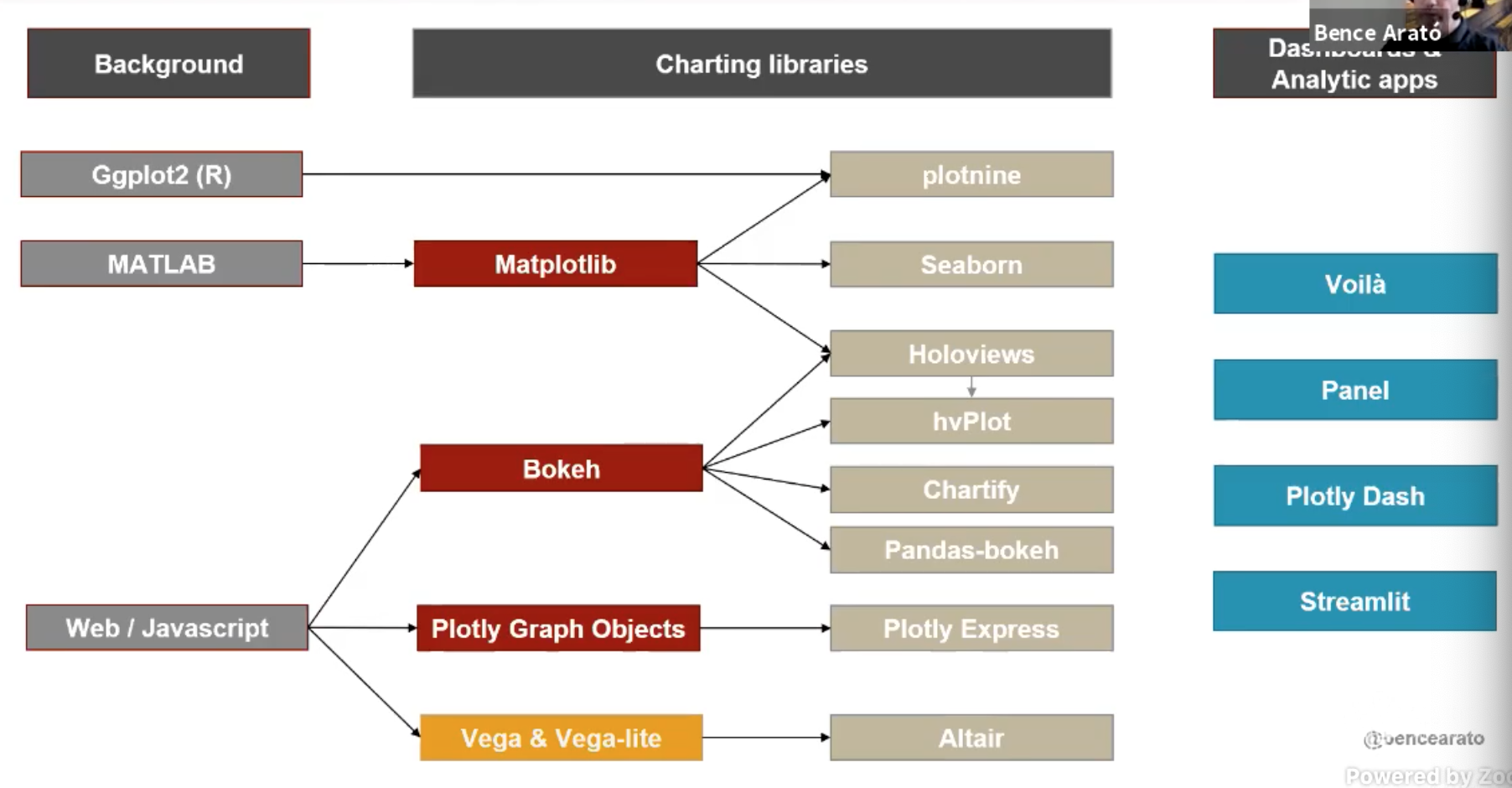
Data Visualisation Landscape, Bence Arato
- See notes or the talk for brief descriptions of the different tools.
- Tools discussed are in image from this slide:
Binder, Sarah Gibson
- For repeatable research (and for teaching/workshops), use Binder
- Just have to give Binder link to your GitHub repo which contains a jupyter notebook and a standard requirements configuration file, and then Binder will create link.
- You give link to somebody, they go to it, and they can run the jupyter notebook from their browser. Super easy
- Binder is open source, so can be configured for your own needs. E.g. can make it so only certain individuals can access the link (or something like that).
- Talk contained details of how Binder works, and the tools and infrastructure they use
IPython, Miki Tebeka
- Did live example of using IPython to do some initial experimentation of data and pre-processing style stuff
- Magic commands with
%, comand line with!,pprintfor pretty printing,?for help,??for source code,%timeitfor time analysis, can do sql with extension,%cowfor ascii art. - See talk for more examples not listed here
Analytical Functions in SQL, Brendan Tierney
- Talk was cancelled, but their slides are available
- Looks like SQL can do a lot more than what most of us know
- Something worth researching
Tricks and tools for efficiency/speed gains
Several talks were about this, so I thought it was worth grouping them together
concurrent.futures, Chin Hwee Ong
- Built in package in Python for parallel / asynchronous computing
- For big data, can use tools like Spark.
- For small big data, overhead cost is too large
- Using concurrent.futures module can speed things up
daal4py and SDC by Intel, Fedotova and Schlimbach
- These are open source tools that can drastically speed things up.
- daal4py gives optimised versions of scikitlearn functions. But still in production. Some functions do not give identical output to their scikitlearn counterparts.
- SDC. A just-in-time compiler. Extension of Numba.
- Easy to use; just add decorate
@numba.jit - Only works for statically compilable code
- Easy to use; just add decorate
- Examples of speed ups provided in the talk
Tips and tricks for efficiency gains in Pandas, Ian Ozsvald
- RAM considerations.
- Use category instead of strings, for low cardinality data
- Use float32 or float16 instead of float64
- Has tool
dtype_dietto automate optimisation of a dataframe
- Dropping to NumPy
- E.g.
df.sum()versusdf.values.sum()
- E.g.
- Some tools
- bottleneck. See talk for example
- dtype_diet
- ipython_memory_usage
- numba, njit wrapper.
- Parallelise with Dask. Use profiling to check if benefit outweighs overhead
- Vaex and modin.
- Our own habits
- Write tests!
- Lots of other examples in their blog and book
30 Rules for Deep Learning Performance, Siddha Ganju
- 30 tips and tricks for deep learning in TensforFlow
- No point repeating them all here. See notes from talk, or watch talk (or buy their book Practical Deep Learning)
Miscellaneous
Tips for Docker, Tania Allard.
- Expect things to be tricky and frustrating. There are many bad tutorials online
- Do not re-invent the wheel: use cookie-cutter, repo2docker
- Many other useful tips in the talk
Data Cleaning Checklist, Hui Zhang Chua
- Hui provided a checklist of tasks you should do when cleaning data.
- Refer to the notes from the talk for the list
History of Jupyter Notebooks, William Horton
- Does what it says on the tin. I stopped taking notes because I do not anticipate learning the history. Watch the talk if you want to know more.
Neural Style Transfer and GANs, Anmol Krishan Sachdeva
- Anmol described the algorithm for GANs and for neural style transfer
- Showed example code in the talk
- See notes for the details. It’s pretty clever stuff!
Probabilistic forecasting with DeepAR, Nicolas Kuhaupt
- DeepAR is an algorithm to produce probabilistic time series predictions, by Amazon
- One interesting feature is it deals with multiple time series simultaneously
- I did not understand details. Would have to read paper to understand
- Example uses cases
- Sales at amazon. Each product has its own time series
- Sales of magazines in different stores. Each store has its own time series.
- Loads on servers in data centers
- Car traffic. Separate time series for each lane
- Energy consumption by household.
- Goes through an example in the talk